One Proxy. Many Clusters. No routing headaches!
Let services/apps live where they make sense. Let teams own their clusters. Let the gateway handle all of them.
That's the promise of multi-cluster networking. And for most teams, it's also where things start to get VERY painful.
The Problem We Keep Solving the Wrong Way
I've had this conversation with enough platform engineering teams to recognize the pattern.
They start with one cluster. Clean, manageable. Then a second cluster appears maybe it's a different region, a different cloud provider, a compliance boundary, or just a team that wanted their own namespace and got a whole cluster instead.
Now they need services from cluster B to be reachable from cluster A and it is a complete headache, isn't?
What Traefik Hub's Multicluster Actually Does
Traefik Hub v3.20 ships with a native multicluster provider. No sidecar overhead. No separate control plane to babysit.
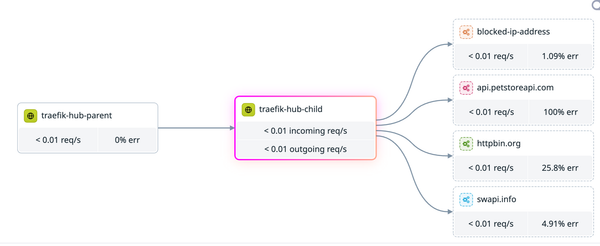
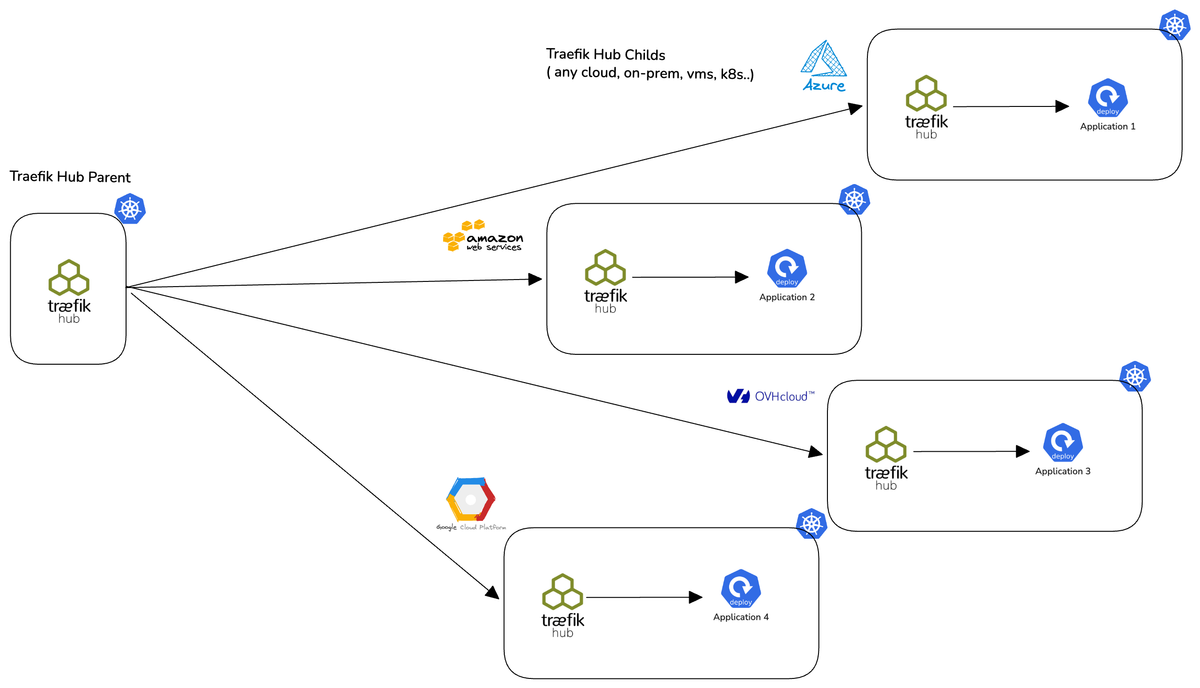
The model is simple: one parent cluster runs Traefik Hub as the entry point. Any number of child clusters expose services via a new CRD called Uplink. The parent polls all of them, discovers uplinked services across every child, and routes traffic to them as if they were local using a clean @multicluster suffix in the IngressRoute.
Setting Up the Parent Cluster
The parent cluster runs Traefik Hub with multicluster enabled in the Helm values:
hub:
providers:
multicluster:
enabled: true
pollInterval: 5
pollTimeout: 5
children:
cluster-1:
address: "https://uplink.cluster-1.traefik.ai:9443"
cluster-2:
address: "https://uplink.cluster-2.traefik.ai:9443"
cluster-3:
address: "https://uplink.cluster-3.traefik.ai:9443"The parent polls each child every 5 seconds. You add as many children entries as you have clusters one block per cluster, each with its own address. When the parent finds an Uplink resource on any of them, it registers that service into its own routing table under the @multicluster provider.
The parent's IngressRoute then routes to the child cluster's service like this:
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: multi-cluster-api
namespace: traefik
spec:
entryPoints:
- web
- websecure
routes:
- match: PathPrefix(`/carlos`)
kind: Rule
services:
- name: apps-api-workload@multicluster
kind: TraefikServiceNotice apps-api-workload@multicluster. That's the Uplink name from the child cluster, namespaced as {namespace}-{uplink-name}@multicluster. The parent doesn't need to know the child's IP, port, or internal topology. It just references the service by name.
Setting Up the Child Cluster
On the child side, you create an Uplink resource to expose a service, and annotate the corresponding IngressRoute to link them:
apiVersion: hub.traefik.io/v1alpha1
kind: Uplink
metadata:
name: api-workload
namespace: apps
spec:
entryPoints:
- multicluster
weight: 10
---
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: api-route
namespace: apps
annotations:
hub.traefik.io/router.uplinks: "apps-api-workload"
spec:
routes:
- match: PathPrefix(`/carlos`)
kind: Rule
middlewares:
- name: strip-carlos
services:
- name: httpbin-svc
port: 443
passHostHeader: false
---
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: strip-carlos
namespace: apps
spec:
stripPrefix:
prefixes:
- /carlosThe annotation hub.traefik.io/router.uplinks: "apps-api-workload" binds the IngressRoute to the Uplink, so the parent knows exactly which routes are reachable via that uplink.
The child also handles its own middleware. The strip prefix happens locally before the request hits the backend. The parent doesn't need to know about it.
Why This Works
The separation of concerns here is clean in a way that service meshes often aren't.
The parent cluster owns the entry point. It decides what's publicly reachable, what paths route where, and which child cluster handles what. It's a policy layer.
The child clusters own their services. Teams deploy their Uplink and IngressRoute alongside their apps. They control what gets exposed and how (middleware, weights, backend ports). No platform team bottleneck.
The gateway does the heavy lifting. TLS termination, path matching, middleware execution, observability. All of it handled at the proxy layer.
And because it's still just Traefik under the hood, you get the full ecosystem: distributed ACME for TLS, OTLP for logs/metrics/traces, IngressRoute CRDs your team already knows.
What's Next
A parent-child topology with declarative service exposure via Uplink, and routing via the familiar @multicluster provider suffix.
If you're running multiple clusters today and work around all of them together, this is worth a look. The setup is a few YAML files and a Helm upgrade. The payoff is a gateway that treats your whole infrastructure as one routing table.
And you?
How are you handling cross-cluster service discovery today?
I'd love to hear what patterns your team is using, and what pain points are still unsolved.