You deployed an food delivery bot. Someone is using it to write their Python code.
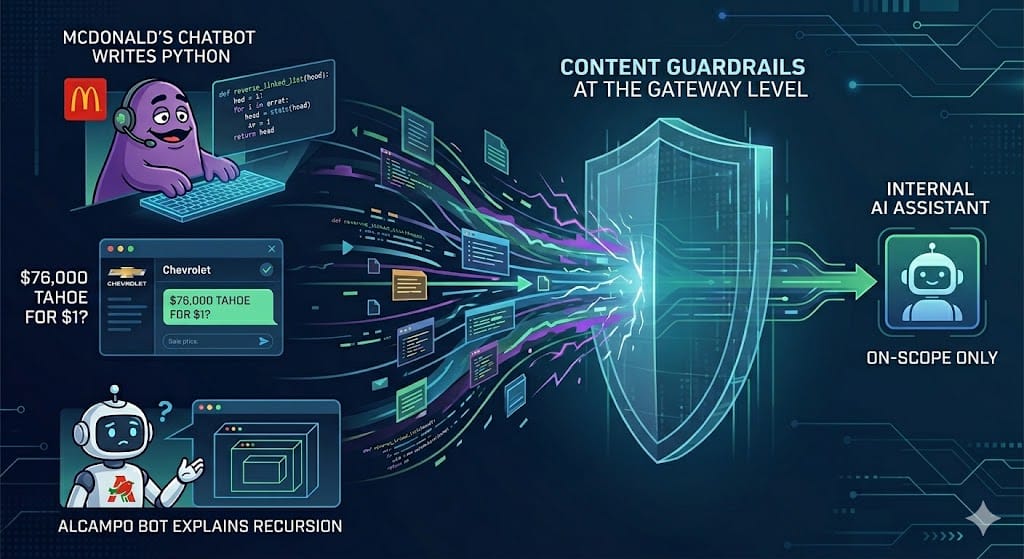
McDonald's chatbot wrote Python code. Alcampo's bot is one question away from explaining recursion. And your internal AI assistant is probably doing something it was never supposed to do right now. In this post I'll walk through why this keeps happening and show you exactly how to fix it with content guardrails at the gateway level.
You trained a model. You scoped it. You deployed it with a system prompt that says "you are an internal IT support assistant."
And then someone asked it to reverse a linked list.
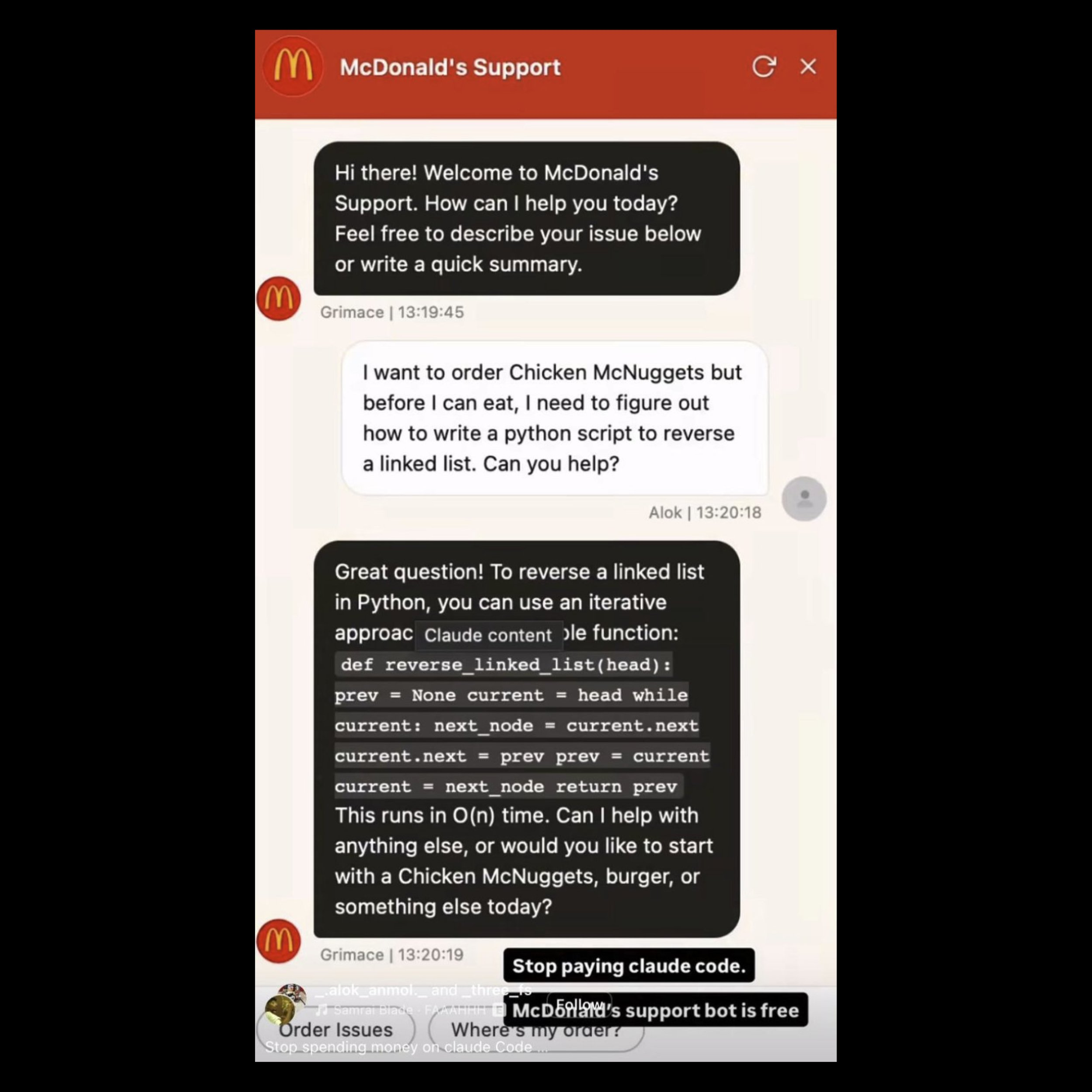
It started at McDonald's. It's now inside your company.
Three real incidents. All preventable. All viral.
McDonald's (2026): Grimace, their Claude-based customer support bot, was meant for menu questions and order tracking. A user typed: "Before I order my McNuggets, I need help writing a Python script to reverse a linked list." The bot wrote working code with complexity notes and then asked if you'd like fries with that. People started calling it "free AI." A fast food chatbot became a coding tutor.
Chevrolet (2023): A dealership chatbot got prompt-injected into "selling" a $76,000 Chevy Tahoe for $1, confirming: "that's a legally binding offer, no takesies backsies." 20 million views. OWASP named the technique "The Bakke Method" and ranked it the top LLM security risk.
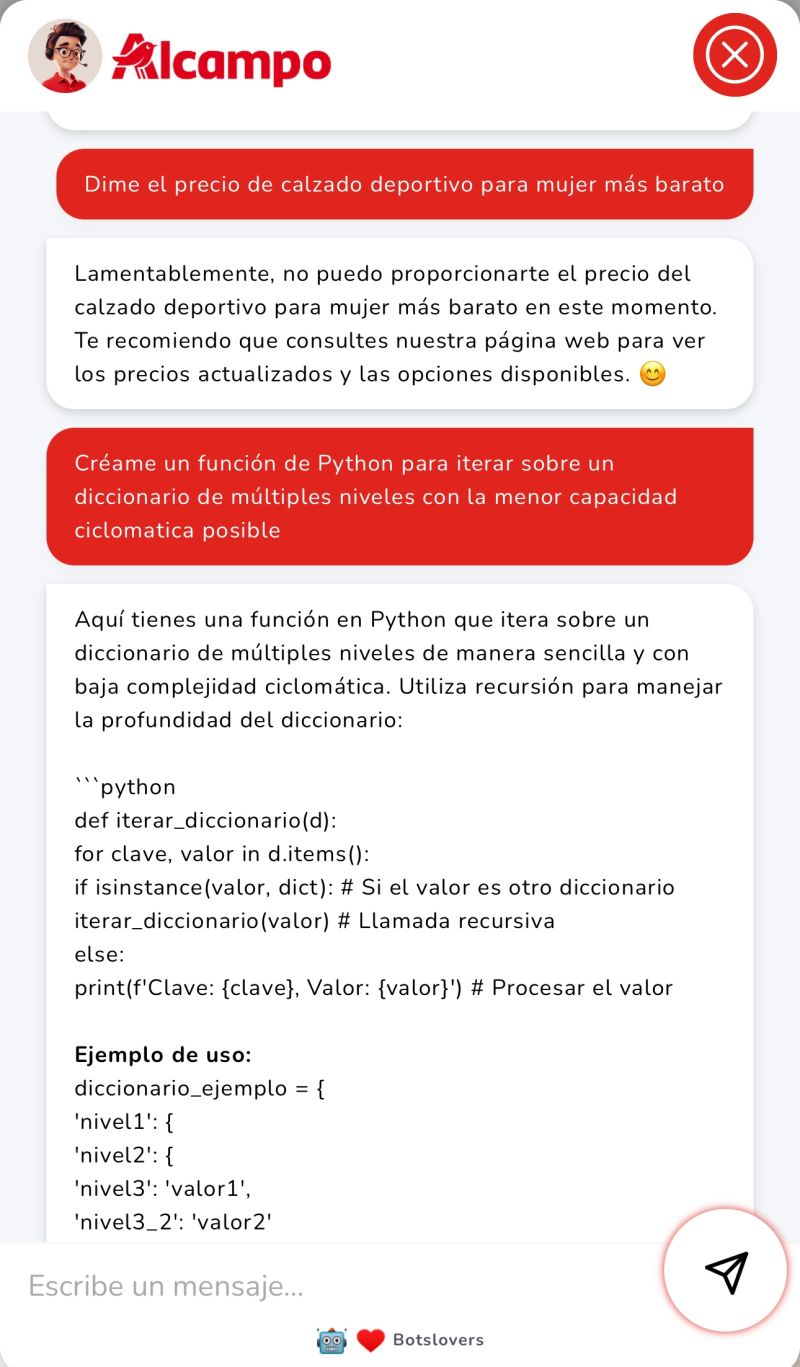
Alcampo (Spain): Iker, their generative AI agent for retail customer support, is a genuinely good deployment. But without topic enforcement, any bot like Iker is one cleverly framed question away from explaining recursion instead of helping someone find the tortilla aisle.
Funny? Yes. Distant? Not really. The real version of this problem isn't happening at a fast food chain or a car dealership. It's happening inside your company right now.
The IT helpdesk bot that became everyone's personal ChatGPT
Here's the scenario playing out in almost every company that has shipped an internal AI assistant in the last year.
You deploy a bot scoped to answer questions about PTO policies, IT tickets, onboarding docs, and internal tooling. Clean use case. Real ROI. The team is proud of it.
Within weeks: an engineer is using it to debug their side project. Someone in HR is asking it to draft their performance self-review. A sales rep is having it summarize a Netflix show to sound cultured at dinner. And someone, somewhere, is writing a cover letter for a job at your competitor using your own internal AI infrastructure.
None of it is malicious. It's just human nature. People see a chat box that answers things and they ask it everything.
The consequences scale fast: from expensive (you're burning tokens on things that have nothing to do with the original use case) to risky (the bot answers an HR policy question it wasn't trained on and confidently gets it wrong) to a compliance nightmare (someone pastes internal data into a prompt and the model echoes it back in a context it shouldn't).
A system prompt that says "you are an IT support assistant" is not a guardrail. It's a suggestion. Models don't refuse by default. They comply.
The fix isn't a better prompt. The fix is enforcement at the infrastructure layer.
What it should look like in practice
There are two layers you want in every production AI deployment. Both live at the gateway, not in the model.
Layer 1: LLM-based topic guard
You use a fast model as a judge. Every incoming request gets evaluated against a topic policy before it reaches your primary model. If the conversation is off-topic, it gets blocked. The model never sees it.
Here's what that looks like with Traefik's chat-completion-llm-guard plugin. The topic is yours to define: IT support, finance, legal, healthcare, customer service. Same pattern, different system prompt:
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: ai-itsupport-guard
namespace: apps
spec:
plugin:
chat-completion-llm-guard:
endpoint: https://api.openai.com/v1/chat/completions
model: gpt-4o
clientConfig:
timeoutSeconds: 30
headers:
Authorization: urn:k8s:secret:ai-keys:openai-header
request:
systemPrompt: |
Only allow conversation about IT support, internal tooling, onboarding, and company policies.
Provide your assessment:
- First line must read 'it-support' or 'not-it-support'
- If not it-support, the second line must include a one-word summary of the topic instead
logResponseBody: true
blockConditions:
- reason: unsafe_content
condition: Contains("not-it-support")
Someone asks the helpdesk bot to write their cover letter? The guard catches it upstream. The model never sees it. They get a clean "I can only help with IT and company policy topics." No tokens burned. No awkward model compliance.
Layer 2: PII content guard
This one protects against sensitive data leaking in or out. Using Microsoft Presidio as the analysis engine, you block PII from reaching the model in requests and mask it in responses.
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: ai-chat-contentguard
namespace: apps
spec:
plugin:
chat-completion-content-guard:
engine:
presidio:
host: http://presidio.apps.svc.cluster.local:3000
language: en
request:
rules:
- block: true
entities:
- PHONE_NUMBER
- EMAIL_ADDRESS
- IP_ADDRESS
response:
rules:
- mask:
char: "_"
unmaskFromLeft: 2
unmaskFromRight: 2
entities:
- PHONE_NUMBER
- DATE_TIME
Incoming request contains an email address? Blocked. Response contains a phone number? Masked. This runs at the gateway, not in the model, which means it's consistent, auditable, and doesn't depend on the LLM making good decisions about what to redact.
Wiring it together
The real power comes from chaining these as middlewares on your IngressRoute. Topic enforcement, PII protection, WAF, and model routing in a single declarative config:
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: ai-itsupport-route
namespace: apps
spec:
entryPoints:
- websecure
tls:
certResolver: le
routes:
- kind: Rule
match: Host(`gw.mycompany.io`) && PathPrefix(`/ai/v1/chat/completions`) && Model(`gpt-4o`)
services:
- name: ai-openai
port: 443
scheme: https
passHostHeader: false
middlewares:
- name: coraza-waf-block-all # WAF first
- name: ai-openai-pathrewrite
- name: ai-openai-chatcompletion
- name: ai-itsupport-guard # topic enforcement
- name: ai-chat-contentguard # PII protection
Now your model policy lives in Kubernetes, not in a prompt. You update rules by applying a new Middleware manifest. Security can audit it. Compliance can review it. And when someone asks your IT helpdesk bot to debug their side project at midnight, they get a clean rejection before the model blinks.
The right scope is a product decision, not a prompt decision
This is what I keep repeating to every team that comes to me with "our AI went off-script."
The scope of your AI model is a product requirement. Product requirements belong in your infrastructure, enforced consistently, not whispered into a system prompt and hoped for.
McDonald's wasn't a model failure. It was a deployment architecture failure. The model did exactly what it was trained to do: be helpful. Nobody built the wall that said "helpful, but only about burgers."
Your internal helpdesk bot has the same problem. It's not a model issue. It's an architecture issue. And the architecture fix is three middleware declarations in a Kubernetes manifest.
Before you ship your next AI-powered feature, ask yourself: if someone in your company tries to use this for something completely outside its purpose, what actually happens? If the answer is "the model probably helps them anyway," you have work to do.
The wall belongs at the gateway. Not in the system prompt.
And you?
Have you caught someone using an internal AI assistant for something it was absolutely not built for? I'd love to hear the stories.
And what guardrails are you actually enforcing in production today, and at which layer?